Originx 创新解法——应用依赖故障篇

依赖故障指应用运行所依赖的环境包括网络、中间件、缓存故障导致应用出现故障。这部分故障的根因并不是应用代码的问题,但是其最终表现形式和应用代码故障表现形式类似,很难区分。本文重点呈现Originx如何针对应用环境所依赖的故障进行根因分析,之前的系列文章请参考:
之前的系列文章: 在线业务的常见全栈故障种类与定位手段
文章中对常见的全栈故障的传统定位方法进行了阐述。
文章中呈现了如何利用Originx的功能对应用程序故障的根因定位。
网络故障
网络连接中断、延迟或丢包
○ 案例:2023年4月,某互联网金融云平台因内部容器云平台的COREDNS服务器群集发生异常,导致整个私有云内的核心交易系统无法正常解析内部服务地址。在接下来的3个小时内,平台的放贷、风控等多个交易系统出现大面积延迟和连接中断,账户查询、委托下单等关键业务无法正常使用。据初步统计,这次故障给金融机构带来的直接经济损失高达数亿元人民币。最终通过手动配置绕过DNS解析,临时恢复关键系统连接,但整体恢复所需时间超过10个小时。事后分析发现,DNS集群全军覆没是由于COREDNS升级之后的bug导致,但是没有完善的监控导致故障发现严重滞后。
如果出现案例描述中的网络故障,需要安装专业的网络流量监控工具,并配备相关专业网络专家才能很好分析出问题。此外,网络监控的基线是非常难建立的,以丢包为例,出现丢包就应该告警吗?那会产生非常多的错误告警
Originx轻松能够帮助用户分析出根因:
Originx的解决之道:
1、在Originx首页,Originx的SLO告警就会针对SLO违约告警
2、同时会分析出可能的故障根因节点,当点击详情之后,每个节点的故障初因列表会被呈现出来
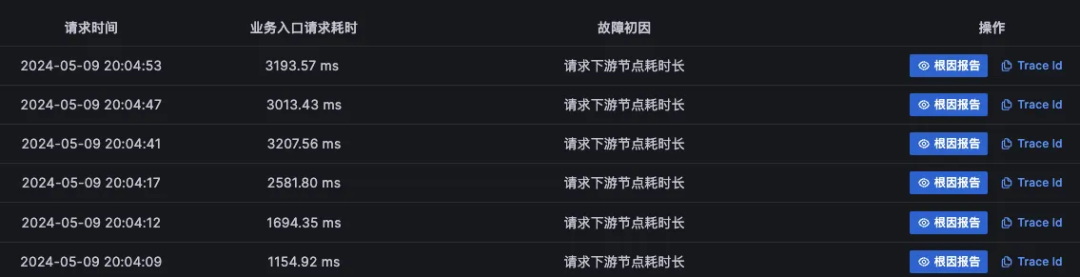
3、根据依赖关系,在疑似的故障根因节点中找到最下游疑似故障节点的故障初因列表,故障初因为“请求下游节点耗时长”,其上游节点多半初因也是这个初因特征,但是上游节点更大概率是由于故障节点级联影响导致,所以应该先验证下游节点的故障根因之后,再排查上游节点的故障根因
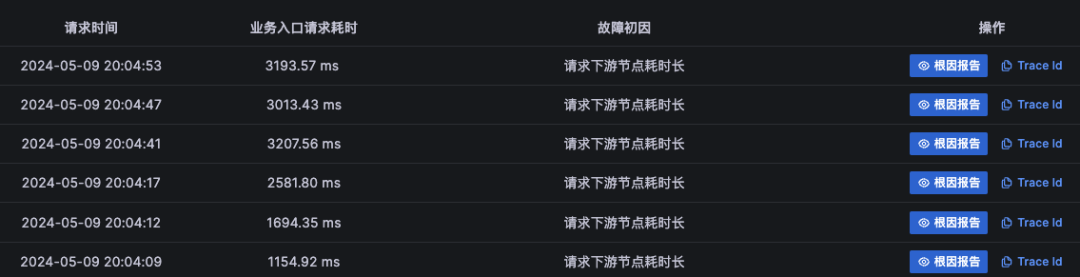
4、在故障报告的报告头部呈现的是故障概览,这里关联了TraceId以��及发生的时间,如果有必要可以使用TraceId去关联分析Tracing数据

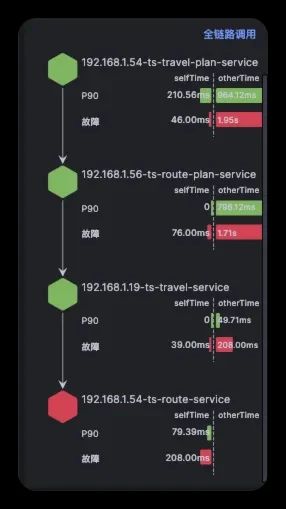
5、在故障报告左边栏中,确认故障传播链路,近似于下图,通过这个数据可以确认在此次报告中故障节点判定是否正确
6、在故障根因中,能够看到根因结论,在多份报告中看到同样的根因报告,这个时候其实可以采取应急手段来恢复业务了,针对本案例的情况: 应急手段就是迁移应用或者切流量了,具体应急措施要看企业之前应急措施准备了哪些条件,如果什么应急手段都没有准备,而且又在云上,可以向云厂商提交工单请求协助处理

7、在故障报告中,以下的数据都是为了提供证据链条来确认故障报告的准确性
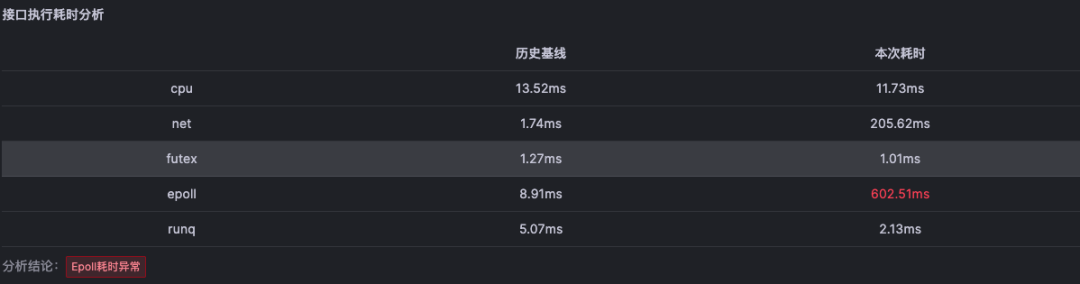
北极星指标(通过北极星指标,Originx给出了异常幅度最大的异常方向,本截图的方向就是网络方向,反映出问题有两种可能,是网络真实有问题也可能是下游执行程序缓慢,网络可能存在真实问题,或者下游执行程序运行缓慢。在后续的分析中,我们将通过评估网络质量来确定是否确实存在网络问题)
接下来会列出所有程序在此次请求中执行过的所有网络请求(某些APM产品可能没有实现插裝就发现不了一些隐藏的网络调用,而Originx从内核判断网络,所有的网络调用一定会出现在这里)

接下来,将深入分析网络请求中耗时最长的部分,以精准定位网络层面的时间损耗原因。(此截图反映网络故障出现在容器网络pod,也就是容器网络有问题)

之后就是通过网络质量指标丢包和延时来进一步证实
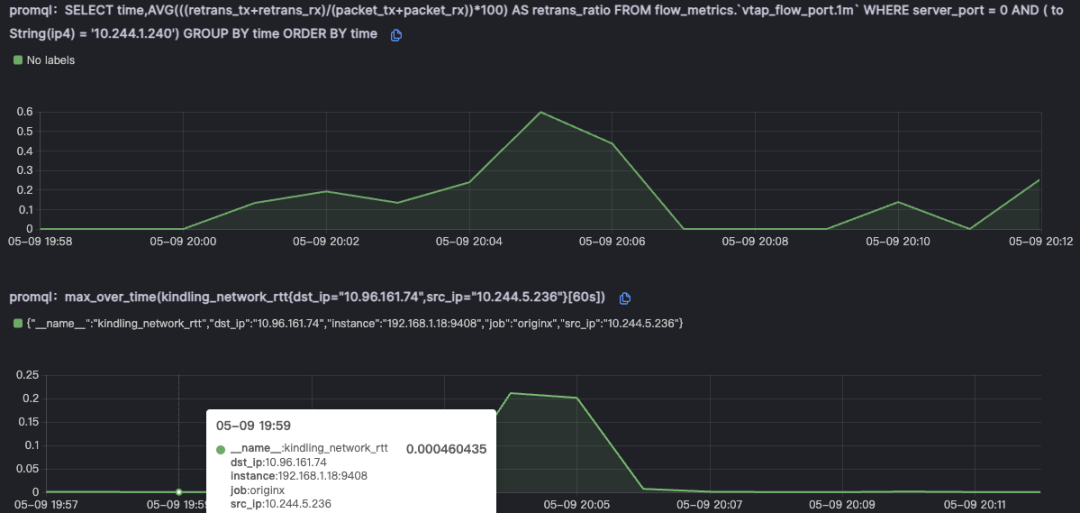
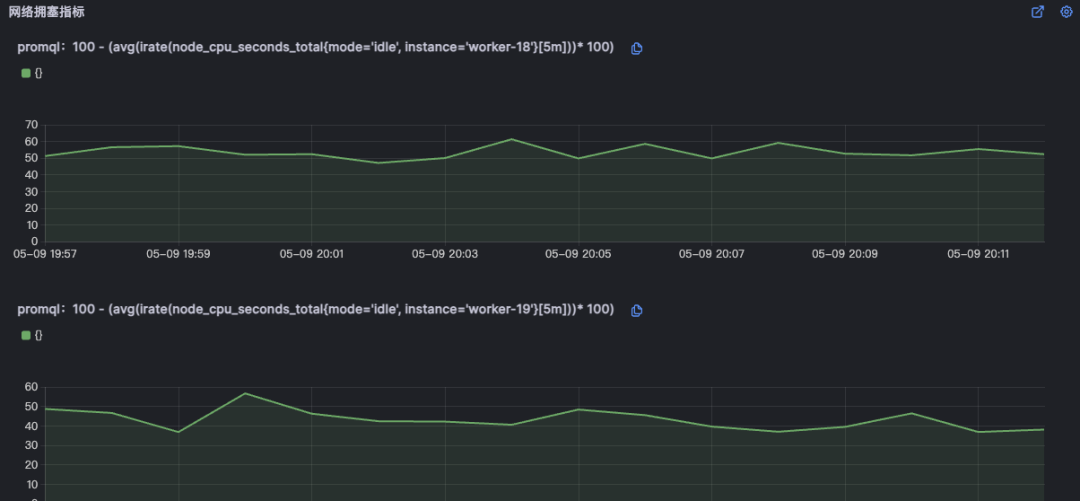
同时还会判断网络拥塞指标,如果当时节点的CPU快耗尽的时候,虚拟网络也会出现丢包,重传的现象
网络配置错误
○ 案例:2022年12月,世界杯决赛期间,某大型视频直播平台由于网络设备配置问题,导致导致网络丢包比例较大,数百万在线用户观看比赛直播受到严重影响,画面频频卡顿中断。该故障持续近2小时,给平台带来了广告收益损失,也影响了品牌声誉。经过紧急处理和优化,网络质量逐步恢复,但已错过了决赛最关键时段。
如果出现案例描述中的网络故障,是交换机的配置错误导致丢包增加,排障流程和之前所说的网络故障是一样的,唯一的区别就是交换机等物理设备导致网�络出现重传和丢包之时,故障耗时是在物理网络段,而不是在虚拟网络段。(由于没法用TC模拟出物理网络出现问题,所以没有办法贴出物理网络有延时的截图,如果真实物理网络有问题应该反映在下图中标红的位置)

缓存故障
缓存命中率下降
○ 案例:2023年6月8日早高峰,某知名新闻平台首页及文章详情页出现加载延迟、频繁超时。原因是缓存服务配置错误导致数据过早过期,高流量下未能及时刷新,与数据库产生数据不一致。经紧急调整缓存策略,禁用部分过期机制并扩容缓存集群,系统逐步恢复。但此次事故影响约200万访问,广告收益损失近百万元。
如果出现案例描述中的缓存命中率下降故障,Originx暂时没有直接给出根因结论。但是Originx仍然能够助力用户更高效的排查出故障根因。缓存命中率下降,意味着程序执行需要额外执行数据查询操作,还有更新缓存操作,这些额外的操作会导致程序执行时的网络时间相较于正常情况有所增加,所以在表现形式上和网络故障很像
Originx的解决之道:��
1、在Originx首页,Originx的SLO告警就会针对SLO违约告警
2、同时会分析出可能的故障根因节点,当点击详情之后,每个节点的故障初因列表会被呈现出来
3、根据依赖关系在疑似的故障根因节点中找到最下游疑似故障节点的故障初因列表,故障初因应该都是“请求下游节点耗时长”,其上游节点多半初因也是这个故障初因特征,考虑级联影响,应该先验证下游节点的故障
4、在故障报告的报告头部呈现的是故障概览,这里关联了TraceId以及发生的时间,如果有必要可以使用TraceId去关联分析Tracing数据(具体截图可以参考之前的案例)
5、在故障报告左边栏中,确认故障传播链路,通过这个数据可以确认在此次报告中故障节点判定是否正确(具体截图可以参考之前的案例)
6、在故障根因报告中,由于Originx现在推理流程还未覆盖缓存对比,现在能看到的报告很可能是未分析出故障根因,如下图所示。故障初因是下游调用耗时长,点击故障报告分析并没有直接给出故障结论,但是初因的结论是准确的,因为实际上网络指标没有任何异常,而且下游节点也没有线程被打满。Originx的推理流程还未覆盖此场景,在不久将来会覆盖此种场景,该场景主要会对比异常网络调用次数和正常网络调用次数,从而判断缓存失效的场景。该故障报告仍然是有用的,可以看出很多问题

7、通过对比北极星指标和具体网络调用次数,可以发现所有的网络调用的执行过程,从中可以发现比正常调用多出了数据库的调用,和缓存调用

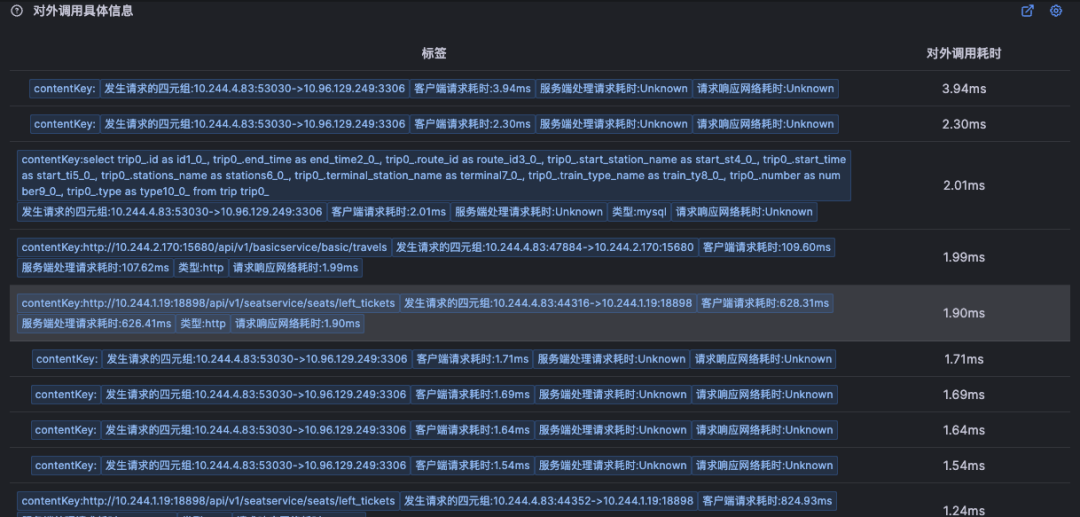
消息队列故障
消息堆积或消费者延迟
○案例:2023年5月15日,某知名电商平台消息中间件所在一台服务器磁盘出现坏道,导致消息写入延迟超10秒。高峰期部分订单消息阻塞,下游服务处理速度骤降80%,造成大量订单挤压及库存操作失败。由于该故障出现较少,SRE专家没有经验,排查期很长,长达1小时才排查出有问题的消息中间件实例,最后经磁盘热插拔修复坏道、调大消息队列容量等应急措施,系统逐步恢复。
如果出现案例描述中消息中间件交互延时下降的场景,不管中间件是由于案例中磁盘坏道导致,还是其它原因导致的,都应该会出现和网络时延类似的场景,故障初因表现为“请求下游节点耗时长”
Originx正在努力支持各种中间件,力争能够针对各种中间件直接给出原因,在还没有覆盖的场景中,仍然可以通过类似于缓存分析的方法,通过分析网络调用细节,从而得到故障根因。具体使用方式和缓存命中率下降是一样的
��外部依赖故障
下游第三方服务调用延迟或失败
○案例:2023年7月6日,某金融科技公司接入第三方支付平台时,遭遇DNS故障导致解析异常,支付请求被调度至香港远程服务节点,网络延时高达200毫秒。当日下午2点开始,订单高峰期大量请求超时失败,支付接入率仅30%。经过一天的排查,终于确定了是第三方支付的DNS解析出现问题,临时固定域名,调用国内支付接口。但仍损失千万元订单手续费收入。
常规公司一般都会对第三方调用做监控,比如利用一些程序做周期访问来判断第三方服务是否正常,如果不正常即告警报错。这种方法固然能够起到一定作用,但是遇到案例中的问题还是比较麻烦,会先入为主的判断第三方服务是没有问题,但是实际业务程序在执行第三方调用和监控程序执行第三方调用并不是按照同一套DNS解析结果执行,这样带来的后果实际两者执行效果不一致。这种问题隐藏很深,很难发现
Originx的排障逻辑其实是一致的,就是当成下游调用去判断,并且得到真实的网络调用IP去判断,如果发现客户端调用异常的数据,然后还会同时判断网络质量是不是正常,最终给出结论,本质上和消息队列故障是一样的判断逻辑
用户仍然是从调用下游耗时长的故障初因切入,然后分析报告得到结论